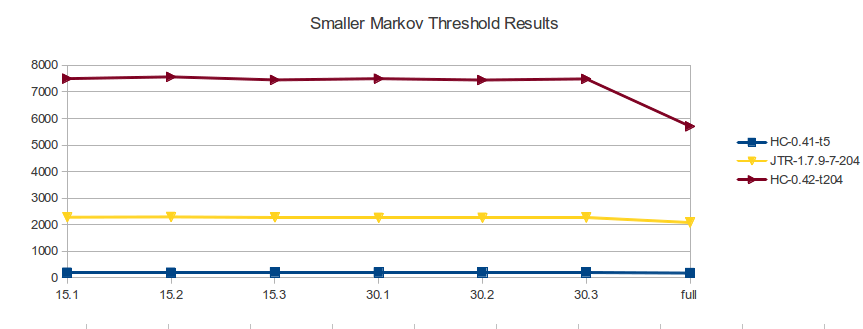
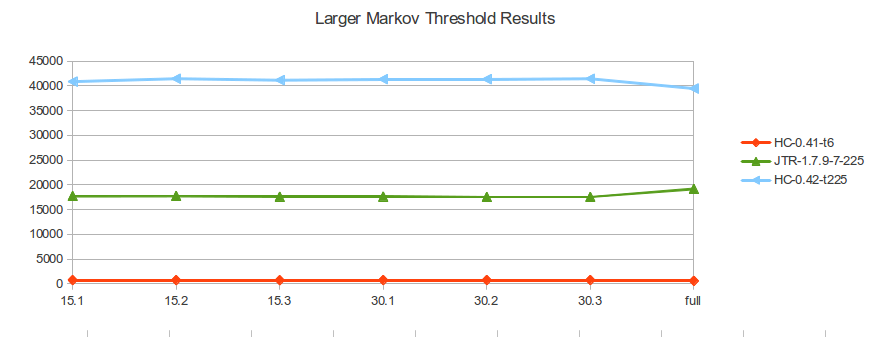
| 15-1 | 15-2 | 15-3 | 30-1 | 30-2 | 30-3 | full | ||
| hashcat 0.41 = --pw-max 12 -t 5 | found | 194 | 194 | 203 | 198 | 201 | 202 | 179 |
|
hashcat 0.41 = --pw-max 12 -t 6
|
found | 745 | 730 | 716 | 742 | 750 | 750 | 581 |
|
1.7.9-7 = ./john -markov:204:0:0:12
|
found | 2282 | 2294 | 2277 | 2262 | 2264 | 2268 | 2082 |
| 1.7.9-7 = ./john -markov:225:0:0:12 | found | 17727 | 17761 | 17596 | 17624 | 17549 | 17552 | 19172 |
| hashcat 0.42 = --pw-max 12 -t 204 |
found |
7501 |
7567 |
7452 |
7499 |
7448 |
7491 |
5703 |
| hashcat
0.42 = --pw-max 12 -t 225 |
found |
40867 |
41457 |
41156 |
41362 |
41352 |
41452 |
39470 |
Or to look at the results differently:
Test - Compare Total unique passwords found
| Training
Set |
Cracked |
Uniq |
New Hashcat Utility Results |
| JTR-1.7.9-7 -> lvl 204 ->
all 15% tests cases combined |
6853 |
2455 | |
| JTR-1.7.9-7 -> lvl 204 -> all 30% tests cases combined | 6794 |
2370 |
|
| JTR-1.7.9-7 -> lvl 204 -> all tests cases combined | 15729 |
2808 -
(17% of total is unique) |
|
| JTR-1.7.9-7 -> lvl 225 -> all 15% tests cases combined | 53084 |
18737 |
|
| JTR-1.7.9-7 -> lvl 225 -> all 30% tests cases combined | 52725 |
18263 |
|
| JTR-1.7.9-7 -> lvl 225 -> all tests cases combined | 124981 |
22633
- (18% of total is unique) |
|
| Hashcat 0.41 -> t5 > all
15% test cases combined |
591 |
249 |
22520 cracked / 16324 unique |
| Hashcat 0.41 -> t5 > all 30% test cases combined | 601 |
215 |
22438 cracked / 8259 unique |
| Hashcat 0.41 -> t5 > all test cases combined | 1371 |
326 -
(23% of total is unique) |
50661 cracked / 17152 (33% of total) unique |
| Hashcat 0.41 -> t6 > all 15% test cases combined | 2191 |
925 |
123480 cracked / 50136 unique |
| Hashcat 0.41 -> t6 > all 30% test cases combined | 2242 |
834 |
124166 cracked / 47026 unique |
| Hashcat 0.41 -> t6 > all test cases combined | 5014 |
1077 - (21% of total is unique) | 287116 cracked / 58509 (20% of total) unique |
..as you can see, the
improvement is quite something. One thing you can see is that there
seems to be more uniqueness in the hashcat runs then JTR. In hashcat.
Now lets do some comparing of the found password sets with one another. For this I created a single file for each tool that had all unique passwords it found in one file. So lets look at the overlap the new hashcat utility had with JTR:
..so unlike last time, there is a lot more overlap between the password attempts both tools tried and the passwords they found. Now lets look at the overlap between the old and new hashcat utility passwords:
..not a lot of overlap. This is another pointer to the impact that the update has had. Now lets run it through a dictionary analyzer and see what other changes the update made:
Now the changes are even more apparent. We can see that the base words found is a lot more useful, there are multiple instances of link, linked, etc. Last time, it did not even find one. Also there are a lot more passwords found in the lower ranges of the password lengths, we can see a lot more 6-8 character passwords were found, last time there was hardly any in this range.
But in the end, the best way to look at it is "did it help me?". Last time I did the test, I took the full passwords found lists from each and tested them against my working copy of the hash list that I am working on. At that time JTR had no new passwords and Hashcat had 3. Since then I have worked through the list a bit more so I was interested to see how the passwords from this new hashcat utility fared:
..it found 11 more passwords I had not yet cracked. Many of my conclusions from the first test remain the same, mainly that JTR and Hashcat do test different passwords, so use both. But I must honestly say that right now, leading with hashcat when you are starting is a good bet, the figures above show that. Hats off to Atom, the update is a great success.
Now lets do some comparing of the found password sets with one another. For this I created a single file for each tool that had all unique passwords it found in one file. So lets look at the overlap the new hashcat utility had with JTR:
| # wc -l ./jtr-all.pass ./new-hc-all.pass 22633 ./jtr-all.pass 58509 ./new-hc-all.pass # grep -xF ./jtr-all.pass -f ./new-hc-all.pass | wc -l 17232 |
..so unlike last time, there is a lot more overlap between the password attempts both tools tried and the passwords they found. Now lets look at the overlap between the old and new hashcat utility passwords:
| # wc -l ./prev.hc-all.pass ./new-hc-all.pass 1077 ./prev.hc-all.pass 58509 ./new-hc-all.pass # grep -xF ./prev.hc-all.pass -f ./new-hc-all.pass | wc -l 249 |
..not a lot of overlap. This is another pointer to the impact that the update has had. Now lets run it through a dictionary analyzer and see what other changes the update made:
| Top 10 base words link = 260 (0.44%) linkedin = 182 (0.31%) linked = 91 (0.16%) jack = 29 (0.05%) mylink = 23 (0.04%) pass = 18 (0.03%) july = 18 (0.03%) mylinkedin = 18 (0.03%) linkme = 18 (0.03%) work = 16 (0.03%) Password length (length ordered) 6 = 9896 (16.91%) 7 = 12567 (21.48%) 8 = 21326 (36.45%) 9 = 8721 (14.91%) 10 = 2831 (4.84%) 11 = 1674 (2.86%) 12 = 1494 (2.55%) Password length (count ordered) 8 = 21326 (36.45%) 7 = 12567 (21.48%) 6 = 9896 (16.91%) 9 = 8721 (14.91%) 10 = 2831 (4.84%) 11 = 1674 (2.86%) 12 = 1494 (2.55%) | | | | | | || || ||| |||| |||| |||| |||| ||||| ||||||| |||||||||||||| 00000000001111 01234567890123 One to six characters = 9896 (16.91%) One to eight characters = 43789 (74.84%) More than eight characters = 14720 (25.16%) |
Now the changes are even more apparent. We can see that the base words found is a lot more useful, there are multiple instances of link, linked, etc. Last time, it did not even find one. Also there are a lot more passwords found in the lower ranges of the password lengths, we can see a lot more 6-8 character passwords were found, last time there was hardly any in this range.
But in the end, the best way to look at it is "did it help me?". Last time I did the test, I took the full passwords found lists from each and tested them against my working copy of the hash list that I am working on. At that time JTR had no new passwords and Hashcat had 3. Since then I have worked through the list a bit more so I was interested to see how the passwords from this new hashcat utility fared:
| >Recovered.: 11/862376 hashes, 0/1 salts |
..it found 11 more passwords I had not yet cracked. Many of my conclusions from the first test remain the same, mainly that JTR and Hashcat do test different passwords, so use both. But I must honestly say that right now, leading with hashcat when you are starting is a good bet, the figures above show that. Hats off to Atom, the update is a great success.